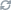


명화를 직접 그릴 필요 없이 문장을 입력하는 것만으로 모작(模作)을 그릴 수 있는 시대가 오고 있다. 시각적 세계를 해석하고 이해하도록 컴퓨터를 학습시키는 인공지능인 컴퓨터 비전의 극한 발전이다.
올해 초 미국 샌프란시스코에 본사를 둔 오픈AI(OpenAI)는 문장을 입력하는 것만으로 고품질 이미지를 생성해 주는 달리2(DALL-E 2)라는 인공지능 이미지 생성기를 선보였다. ‘우주 비행사가 말을 타고 달을 달리고 있다’라는 문장을 입력하면 마치 현대 미술과 같은 작품들을 얻어낼 수 있다. 또 위치, 빛, 그림자, 질감 등을 문장으로 입력하면 그림의 완성도는 더욱 높아진다. 특히 달리2는 요하네스 베르메르의 1665년 작품 ‘진주 귀고리를 한 소녀’에 대한 모작들을 원본과 유사하게 대기원근법인 스푸마토 기법으로 처리해 주목을 끌었다. 모작들은 실제 베르메르가 그린 듯한 착각을 불러일으킬 정도다.
생생한 그림 생성이 가능해진 것은 그동안 컴퓨터 비전에 주로 쓰인 모델인 GAN(Generative Adversarial Networks)을 뛰어넘는 이른바 ‘디퓨전 모델(Diffusion model)’이 개발됐기 때문이다. GAN은 이미지를 생성하는 ‘생성자(generator)’와 해당 이미지가 진짜인지 가짜인지 판별하는 ‘판별자(discriminator)’를 만들어 상호간 경쟁을 붙이는 방식이다. 생성자가 이미지를 만들어 내면 판별자가 진위 여부를 판단하는데, 이를 반복하면서 그림의 정확도를 높이는 구조다. 가짜로 판별이 나면 생성자는 판별자가 인식할 수 없을 때까지 더 진짜 같은 그림을 반복해 그려낸다. 하지만 단점이 명확하다. 생성자가 그럴듯한 이미지를 만들어 판별자를 속이는 데 성공한다면, 생성자는 이와 유사한 이미지만을 골라 생성하기 시작한다.
이에 반해 디퓨전은 노이즈를 연속해서 학습시킨 뒤 이를 역으로 적용한다. 마치 초고해상도 사진을 백지가 될 때까지 문질러, 다시 이를 반대로 백지에서 초고해상도 사진으로 바꾸는 작업과 비슷하다고 할 수 있다. 백지 상태에서 그림을 그리기 때문에 유사 그림에 대한 생성 문제가 없고 매우 창조적이고 다양한 그림을 그릴 수 있다.

창조적 혁신은 늘 빠르게 확산한다. 오픈AI의 인공지능 달리는 큰 자극이 됐다. 구글 브레인, LG, 카카오 브레인 등이 이미지 생성기를 속속 선보였다.
오늘날 컴퓨터 비전은 패션, 의료, NFT(대체불가능토큰) 산업에 빠르게 확산 중이다. 미디어도 예외는 아니다. 미국 미디어에서는 컴퓨터 비전을 활용한 실험들이 이어지고 있다. 미국 테니스협회는 IBM과 협력해 US오픈 경기의 하이라이트를 자동으로 생성해 소셜미디어에 공유하고 있다. 또 MIT미디어랩에서 분사한 어펙티바는 CBS 등과 협업해 콘텐츠를 보고 있는 시청자들의 반응을 알고리즘으로 분석해 낸다. 어떤 부분에서 시청자들이 좋아하고 싫어했는지 등 감정을 판별해 실시간 피드백을 받는 것이다. 또 LG의 인공지능 엑사원은 문장을 이미지로, 이미지를 문장으로 양방향으로 바꿔주는 서비스를 처음 선보였다. 그림 한 장을 업로드하면 영어 기준으로 64개 토큰(말뭉치 단위)에 달하는 문장을 생성한다. 언젠가 사진 설명을 일일이 쓸 필요가 없어질지도 모른다.
물론 인공지능이기에 편향성 염려는 여전하다. ‘폭탄을 든 테러리스트’라고 입력할 경우 특정 인종으로 그림을 그릴 수 있는 것이다. 아울러 엔지니어, 의사, 과학자와 같은 높은 교육 수준을 받은 사람들은 백인으로, 간호사 비서 등은 여성으로 종종 표현된다. 때문에 현재 오픈AI는 상업적 용도로 해당 프로그램을 배포하지는 않았다.
그럼에도 오늘날 인공지능의 물결은 너무나 거세다. 미디어에 인공지능을 결합하는 이른바 ‘미디어 지능화’는 선택이 아닌 필수가 되고 있다.
Copyright @2004 한국기자협회. All rights reserved.

많이 읽은 기사
(우)04520 서울특별시 중구 세종대로 124 프레스센터 1303호 한국기자협회
사무국: 02)734-9321~3 , 편집국: 02)737-2483 | FAX: 02-738-1003
제호: 기자협회보 | 등록번호: 서울 다06478(주간) | 등록일: 1981년 7월7일
제호: 기자협회보 | 등록번호: 서울 아56489(인터넷) | 등록일: 2026년 4월9일
발행인·편집인: 박종현 | 편집국장·청소년보호책임자: 김고은
본지는 한국신문윤리위원회의 서약사로서 신문윤리강령을 준수합니다.
Copyright @2004 한국기자협회. All rights reserved.
한국기자협회와 기자협회보의 명칭과 로고와 콘텐츠(기사, 영상, 사진)는 본 협회 소유 고유재산입니다.
이를 무단으로 사용하거나 오용할 시, 법적 문제가 발생할 수 있으니 유의하여 주시기 바랍니다.